부하 생성
구성한 KEDA ScaledObject에 대한 응답으로 KEDA가 배포를 스케일링하는 것을 관찰하려면 애플리케이션에 부하를 생성해야 합니다. hey를 사용하여 워크로드의 홈 페이지를 호출하여 이를 수행합니다.
아래 명령은 다음과 같이 부하 생성기를 실행합니다:
- 3개의 워커가 동시에 실행
- 각각 초당 5개의 쿼리 전송
- 최대 10분 동안 실행
~$export ALB_HOSTNAME=$(kubectl get ingress ui -n ui -o yaml | yq .status.loadBalancer.ingress[0].hostname)
~$kubectl run load-generator \
--image=williamyeh/hey:latest \
--restart=Never -- -c 3 -q 5 -z 10m http://$ALB_HOSTNAME/home
ScaledObject를 기반으로 KEDA는 HPA 리소스를 생성하고 HPA가 워크로드를 스케일링할 수 있도록 필요한 메트릭을 제공합니다. 이제 애플리케이션에 요청이 도달하고 있으므로 HPA 리소스를 관찰하여 진행 상황을 확인할 수 있습니다:
~$kubectl get hpa keda-hpa-ui-hpa -n ui --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-ui-hpa Deployment/ui 7/100 (avg) 1 10 1 7m58s
keda-hpa-ui-hpa Deployment/ui 778/100 (avg) 1 10 1 8m33s
keda-hpa-ui-hpa Deployment/ui 194500m/100 (avg) 1 10 4 8m48s
keda-hpa-ui-hpa Deployment/ui 97250m/100 (avg) 1 10 8 9m3s
keda-hpa-ui-hpa Deployment/ui 625m/100 (avg) 1 10 8 9m18s
keda-hpa-ui-hpa Deployment/ui 91500m/100 (avg) 1 10 8 9m33s
keda-hpa-ui-hpa Deployment/ui 92125m/100 (avg) 1 10 8 9m48s
keda-hpa-ui-hpa Deployment/ui 750m/100 (avg) 1 10 8 10m
keda-hpa-ui-hpa Deployment/ui 102625m/100 (avg) 1 10 8 10m
keda-hpa-ui-hpa Deployment/ui 113625m/100 (avg) 1 10 8 11m
keda-hpa-ui-hpa Deployment/ui 90900m/100 (avg) 1 10 10 11m
keda-hpa-ui-hpa Deployment/ui 91500m/100 (avg) 1 10 10 12m
오토스케일링 동작에 만족하면 Ctrl+C로 watch를 종료하고 다음과 같이 부하 생성기를 중지할 수 있습니다:
~$kubectl delete pod load-generator
부하 생성기가 종료되면 HPA가 구성에 따라 최소 수로 복제본 수를 천천히 줄이는 것을 확인할 수 있습니다.
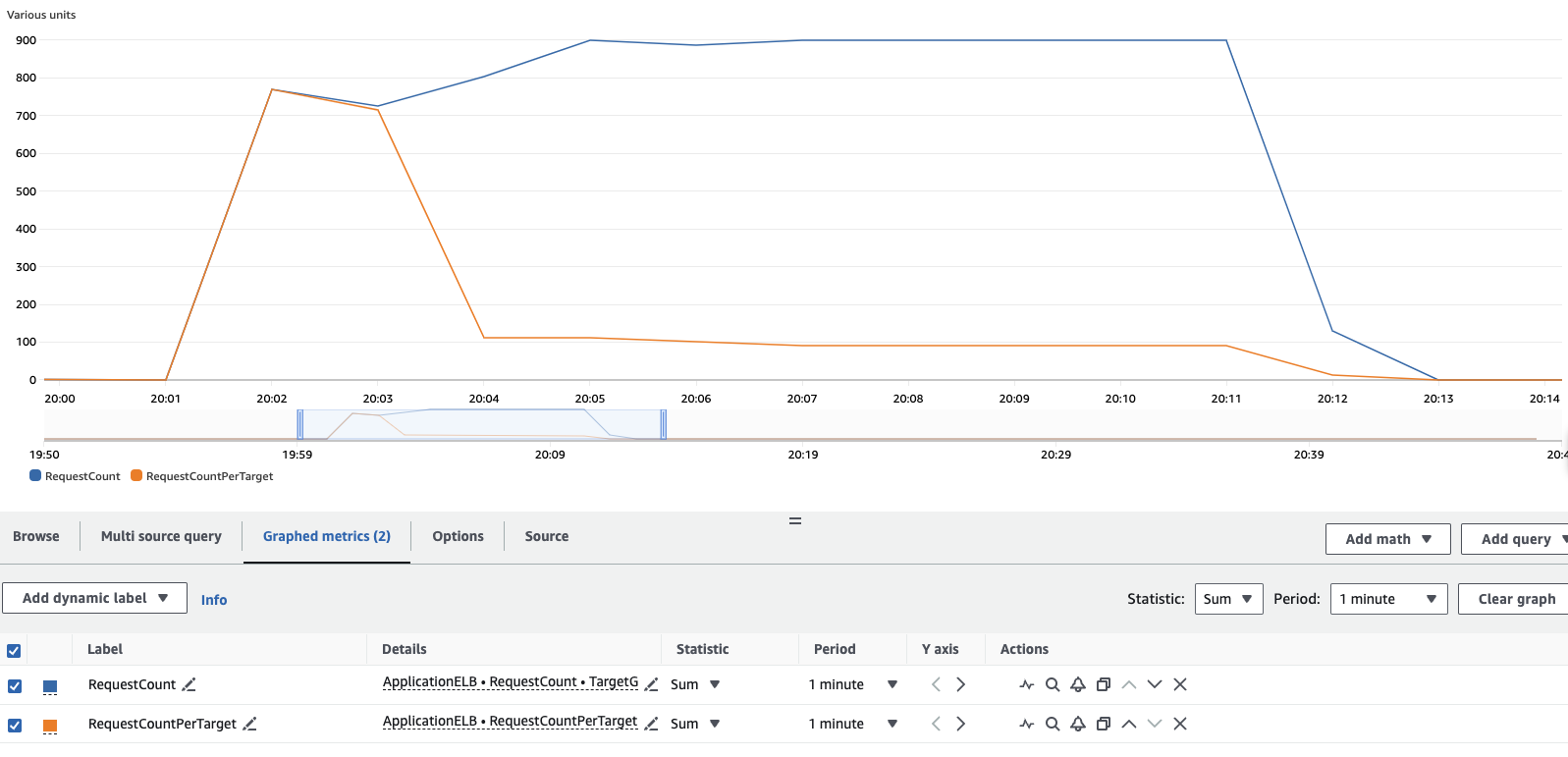
CloudWatch 콘솔에서도 부하 테스트 결과를 확인할 수 있습니다. 메트릭 섹션으로 이동하여 생성된 로드 밸런서와 타겟 그룹에 대한 RequestCount 및 RequestCountPerTarget 메트릭을 찾습니다. 결과를 보면 처음에는 모든 부하가 단일 Pod에 의해 처리되었지만, KEDA가 워크로드를 스케일링하기 시작하면서 요청이 워크로드에 추가된 추가 Pod에 분산되는 것을 확인할 수 있습니다. load-generator Pod를 전체 10분 동안 실행하면 다음과 유사한 결과를 볼 수 있습니다.